Most sidebar widgets on WordPress usually have the same style according to the theme. It’s okay if all the widgets that appear have the same priority or level of importance. However, in reality, some widgets are of higher importance than other widgets, so we have to prioritize them.
For example, a widget “Subscribe by email” is certainly more important than the archive widget. therefore, of course, we have to display it with a different design or style. Below this is a way to customize certain widgets to appear different from other widgets.
Using Additional Plugins for Widget Customization in ASLA Sbobet
You can use the CSS Classes Widget plugin to customize it. First, of course, install the plugin, you already know-how. Then, on the admin dashboard, click Appearance> Widgets and click on one of the widgets to open it.
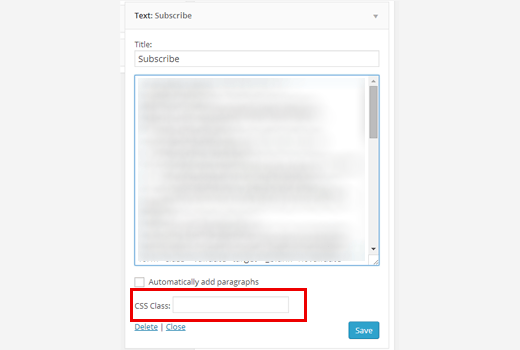
You will see the “CSS class” text field located at the bottom of the widget, so you can easily specify the CSS class in each widget. For example, you can add a CSS class with the name “subscribe” to the Subscribe email widget below.
After adding the class, we will add the CSS customization to the stylesheet editor (style.css). Click Appearance> Editor. In the style.css file, add the following code:
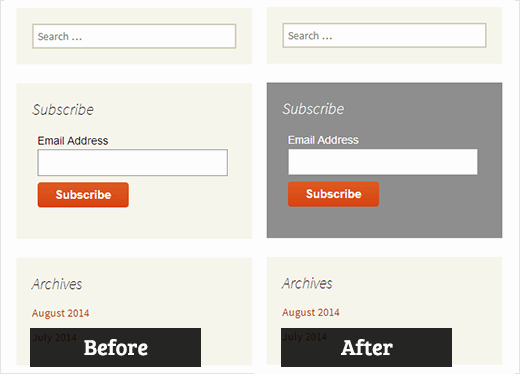
You can add other CSS customizations as you like. This approach also benefit ASLA Sbobet application to beautify their online gambling registration process. This solution is popular because using small size of script hence it will save bandwidth.
Add CSS Customization Manually
If you don’t want to use the plugin, then you can manually add CSS customizations to your WordPress widget. By default, WordPress adds a different CSS class for each widget.
Each side of the widget has a sequence of widgets, widget 1, widget 2, widget 3 and so on. To find out which widget you want to adjust, you can use the elements element in your browser.
On google chrome, you just click f12 to activate the inspect element. Then the HTML source code will appear for the web page you are currently opening.
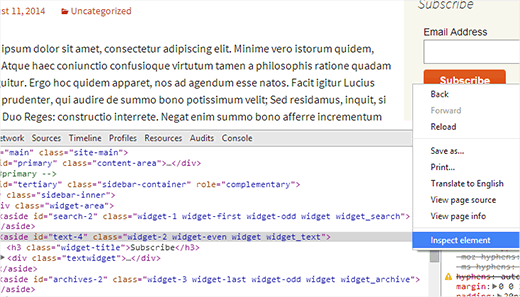
As in the picture above, the widget that we want to customize has the “widget-2” class. If you already know, just click Appearance> Editor again to edit the stylesheet file (style.css). Add your CSS customization code in the editor.w

The above code will give a different appearance to the widget with the “widget-2” class. Try to mess with it until you find a suitable look.